Dieser Blog-Post basiert auf dem Working Paper mit dem Titel Fueling Structural Power: Discursive Strategies in Direct Democratic Climate Politics, welches hier zu finden ist. Der dazugehörende Code mit Dummy Daten liegt auf Github. Die Originaldaten dürfen aufgrund kommerzieller Restriktionen nicht geteilt werde, deshalb ist mit dem Code nur das Vorgehen reproduzierbar, aber nicht die Ergebnisse.
Aktuell ziehen wieder Hitzewellen über Europa und die Klimapolitik der Regierungen ist, angesichts der empirischen Realität, welche selbst die pessimistischen Prognosemodelle übertrifft immer noch ein Hohn. Dies hat auch damit zu tun, dass fossile Brennstoffe für die kapitalistische Produktionsweise zentral sind und die Lobbys der Fossilindustrie mächtig.
Für eine Seminararbeit habe ich mir vor einigen Jahren angeschaut, wie sich Arbeitgeberverbände 2021 in der Schweiz vor der Abstimmung über die Totalrevision des CO2-Gesetzes in der Schweiz in öffentlichen Medien positioniert haben. Die Gesetzesrevision wurde relativ unerwartet durch die Stimmbevölkerung abgelehnt, obwohl zu Beginn der Abstimmungsphase die Zustimmung noch hoch war. Während der Meinungsbildungsphase hat also ein grösserer Umschwung stattgefunden.
Obschon sich viele Arbeitgeberverbände aus unterschiedlichen Branchen klar für die Revision positionierten, gab es - wenig erstaunlich - viel Gegenwind aus der Branche der Fossilindustrie, welche auch massgeblich dazu beigetragen hat, dass überhaupt ein fakultatives Referendum zu Stande kam.
Vor direktdemokratischen Abstimmungen bilden sich Meinungen der Stimmbürger:innen in der Regel sehr nahe an medialen Debatten. Dabei sind die Printmedien immer noch die relevantesten Medien. Die Vermutung lag also nahe, dass sich Wirtschaftsverbände aus der Fossilindustrie medial stark in die öffentliche Debatte einbringen und Stimmung gegen die Revision machen, damit sie in der Abstimmung doch noch gekippt werden kann. Ich wollte deshalb wissen, welche Verbände sich wie stark positionieren und habe dafür ein quantitatives Verfahren entwickelt, welches versucht, die Stärke der Positionierung sichtbar bzw. messbar zu machen.
Datenquellen
Als Datengrundlage habe ich über die Platform Swissdox@Liri der Universität Zürich mit dem Suchbegriff “CO2-Gesetz” (in Titel oder Untertitel) 561 Artikel aus Deutschschweizer Zeitungen heruntergeladen, welche zwischen 14. März 2021 und 04. Juni 2021 - der heissen Phase im Abstimmungskampf - publiziert wurden.
load("articles_UTF8.RData") #
articles <- articles %>% distinct(id, .keep_all=T) %>% # remove duplicate ID's
filter(!grepl("Leser*", rubric, ignore.case = T)) %>%
filter(!grepl("Leser*", lead, ignore.case = T))
df <- articles # use a new variable to have a backup
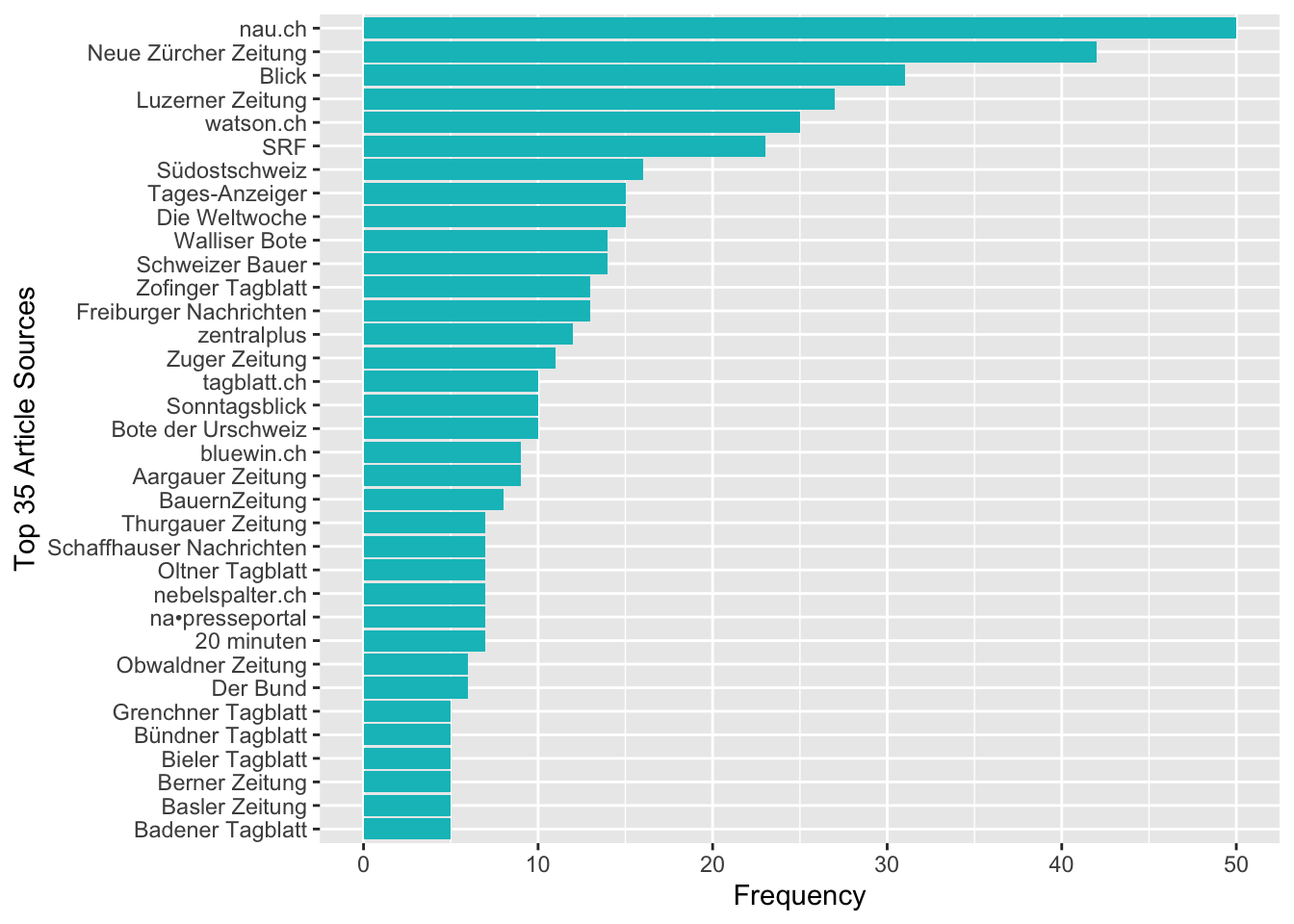
Nach etwas Text-Preprocessing hatte ich eine Auswahl an Artikeln aus 84 unterschiedlichen Quellen, davon viele von nau.ch, der NZZ und dem Blick:
article.sources <- df %>% count(medium_name) %>% arrange(desc(n))
article.sources %>% nrow()
## [1] 84
#kwic_assocs %>% distinct(docname) %>% nrow() # count found articles
ggplot(head(article.sources, 35), aes(reorder(medium_name, n), n)) +
geom_bar(fill=hcl(195,100,65), stat="identity") + coord_flip() +
xlab("Top 35 Article Sources") + ylab("Frequency")
Zusätzlich habe ich eine Liste von 312 Wirtschaftsverbänden in der Schweiz erstellt. Die Namen der einzelnen Verbände wurden von den Websiten der drei Wirtschaftsdachverbänden Economiesuisse, Schweizerischer Arbeitgeberverband und Schweizerischer Gewerbeverband gescraped und in einer Excelliste gespeichert. Handelskammern und Einzelmitglieder habe ich entfernt:
# Load Swiss interest groups dataset
swiss_assocs <- read_excel(paste(getwd(), "Associations_Economic.xlsx", sep="/"), sheet = "Liste")
# filter out Handelskammern
swiss_assocs <- swiss_assocs %>% filter(is.na(Verbandstyp) | Verbandstyp != "Handelskammer")
swiss_assocs <- swiss_assocs %>% filter(is.na(Verbandstyp) | Verbandstyp != "Einzelmitglied")
swiss_assocs %>% nrow()
## [1] 312
swiss_assocs %>% select(Shortname, Name) %>% arrange(Shortname) %>% print()
## # A tibble: 312 × 2
## Shortname Name
## <chr> <chr>
## 1 2rad Schweiz Branchenverband des Schweizer Fachhandels für Zweiradfahrzeuge
## 2 ACS Automobil Club Schweiz
## 3 AGV Rheintal Arbeitgeberverband Rheintal
## 4 AGVS Auto Gewerbe Verband Schweiz
## 5 AITI Association of Ticino’s industries
## 6 AM Suisse Arbeitgeberverband Landtechnik, Metallbau, Hufschmiede
## 7 AM Switzerland Asset Management Association Switzerland
## 8 APHM Association Patronale de l'Horlogerie et de la Microtechnique
## 9 ASCO Association of Management Consultants Switzerland
## 10 ASEPIB Association Suisse d'Esthéticiennes Propriétaires d'Instituts…
## # ℹ 302 more rows
Analyse
1. Konkordanzen finden: Welche Wirtschaftsverbände tauchen auf?
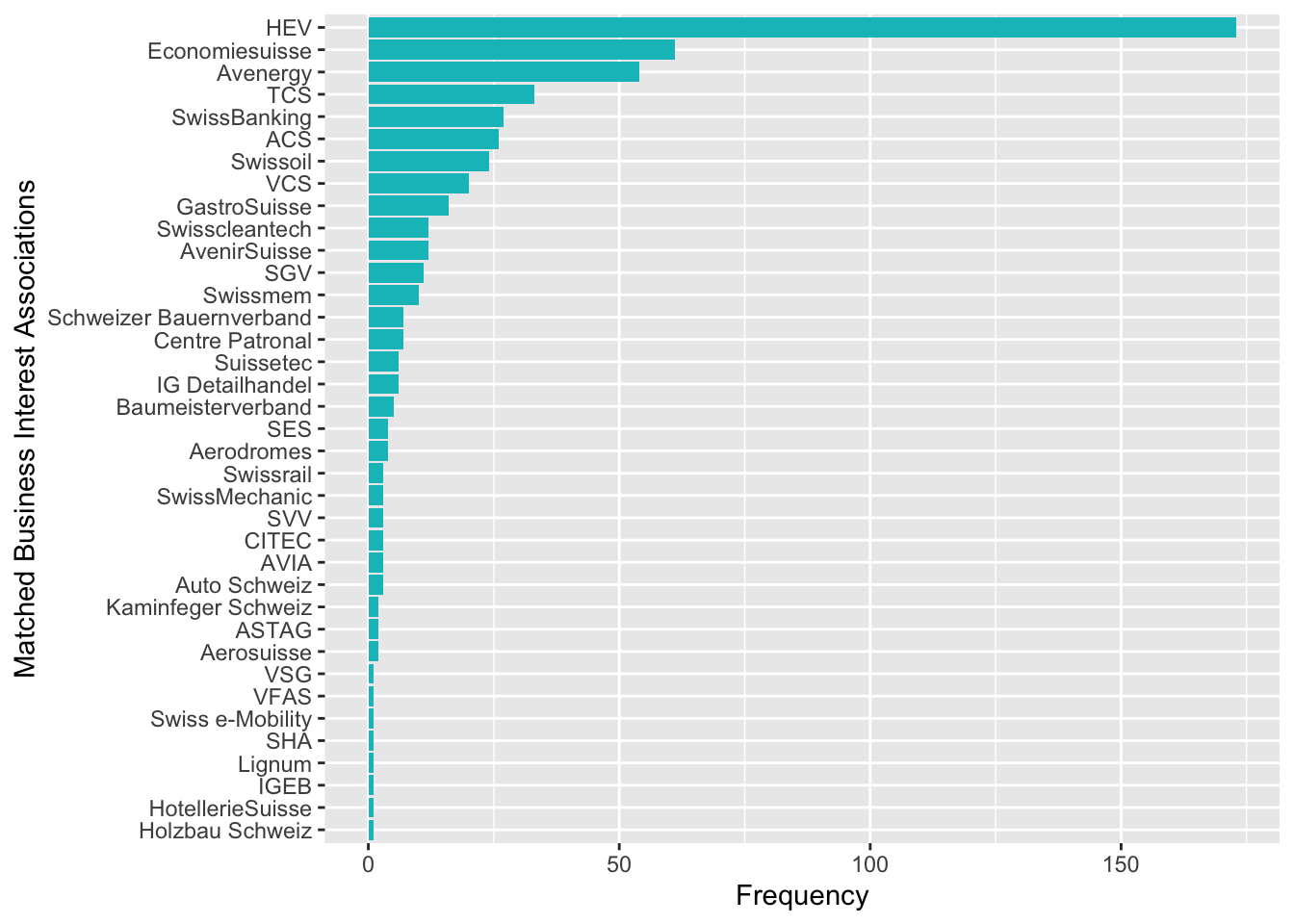
In einem ersten Schritt habe ich für die Textanalyse einen Textcorpus mit quanteda erstellt und in den Zeitungsartikeln nach den vollen Namen oder den abgekürzten Bezeichnungen der Wirtschaftsverbände gesucht. Mittels Keyword-In-Context (KWIC) habe ich für jeden gefundenen Begriff jeweils ein Textfenster von 50 Tokens, das heisst 25 Wörtern um den gefundenen Verbandsnamen, extrahiert. Dadurch werden in den Artikeln 161 Textstellen gefunden, in welchen insgesamt 38 Verbände genannt werden. Besonders stark sticht hierbei der Hauseigentümerverband (HEV) ins Auge, aber auch verschiedene Verbände der Fossilindustrie (Avenergy, Swissoil) oder der Auto-Lobby (ACS, TCS) sind stärker vertreten.
############### 1. Interest group concordances ################
# create a quanteda corpus
corpus <- corpus(df)
# also create a dataframe with the metadata and document names from the corpus that can later be used to join with kwic-dataframes
docnames <- as.data.frame(docnames(corpus))
names(docnames) <- c("Text")
corpus.vars <- bind_cols(docnames, docvars(corpus))
rm(docnames)
# tokenize data
tokens <- tokens(corpus, remove_url=T)
# find concordances
assocs_search_short <- swiss_assocs %>% distinct(Shortname) %>% na.omit()
assocs_search_long <- swiss_assocs %>% distinct(Name) %>% na.omit()
searchvector <- c(assocs_search_short$Shortname, assocs_search_long$Name)
rm(assocs_search_long, assocs_search_short)
kwic_assocs <- kwic(tokens, window=50, pattern = phrase(searchvector))
# recreate new text field from concordance context and remove duplicates
kwic_assocs <- kwic_assocs %>%
rowwise() %>%
mutate(text = paste(pre, pattern, post)) %>%
mutate(pattern = ifelse(pattern %in% swiss_assocs$Name, (swiss_assocs %>% filter(Name == pattern))$Shortname, (swiss_assocs %>% filter(Shortname == pattern))$Shortname)) %>% #Substitute long/shortnames
ungroup() %>%
distinct(text, .keep_all=T) # remove duplicates
# count matches
assoc.matches <- kwic_assocs %>% count(pattern) %>% arrange(desc(n)) # count matched BIAs
kwic_assocs %>% distinct(docname) %>% nrow() # count found articles
## [1] 161
# join this data with the associations dataset in order to have interest group categories
kwic_assocs <- kwic_assocs %>%
left_join(swiss_assocs, by=c("pattern" = "Shortname")) %>% # add association variables
left_join(swiss_assocs, by=c("pattern" = "Name")) %>%
unite(Category, Category.x, Category.y, na.rm=T) %>%
unite(Category2, Category2.x, Category2.y, na.rm=T) %>%
left_join(corpus.vars, by=c("docname" = "Text")) %>% # add original article metadata
left_join(assoc.matches, by=c("pattern" = "pattern")) %>% # add match count
distinct(text, .keep_all=T)
# Plot
ggplot(assoc.matches %>% drop_na(), aes(reorder(pattern, n), n)) +
geom_bar(fill=hcl(195,100,65), stat="identity") + coord_flip() +
xlab("Matched Business Interest Associations") + ylab("Frequency")
2. Dictionary Analyse der Text-Tonalität
Die gefundenen Textpassagen werden nun mittels einer Dictionary-Analyse auf ihre Tonalität untersucht um zu prüfen, ob sich der Text eher positiv oder negativ auf die zur Abstimmung stehende Totalrevision des CO2-Gesetzes bezieht. Dafür verwende ich einerseits Rauh’s German Political Sentiment Dictionary, welches in quanteda direkt inkludiert ist:
################ 2. Operationalization of positioning scores ################
# create new corpus from found article parts
corpus_assocs <- corpus(kwic_assocs)
# Rauh's German dictionary (loaded via quanteda.sentiment)
tokens.assocs <- tokens(corpus_assocs) %>% tokens_remove(stopwords("de")) %>% tokens_tolower()
dfm.senti.rauh <- tokens.assocs %>%
tokens_lookup(dictionary = data_dictionary_Rauh) %>%
dfm()
df.senti.rauh <- dfm.senti.rauh %>% convert(to = "data.frame") %>%
mutate(sentiment = positive - negative) # calculate a combined sentiment score for regression
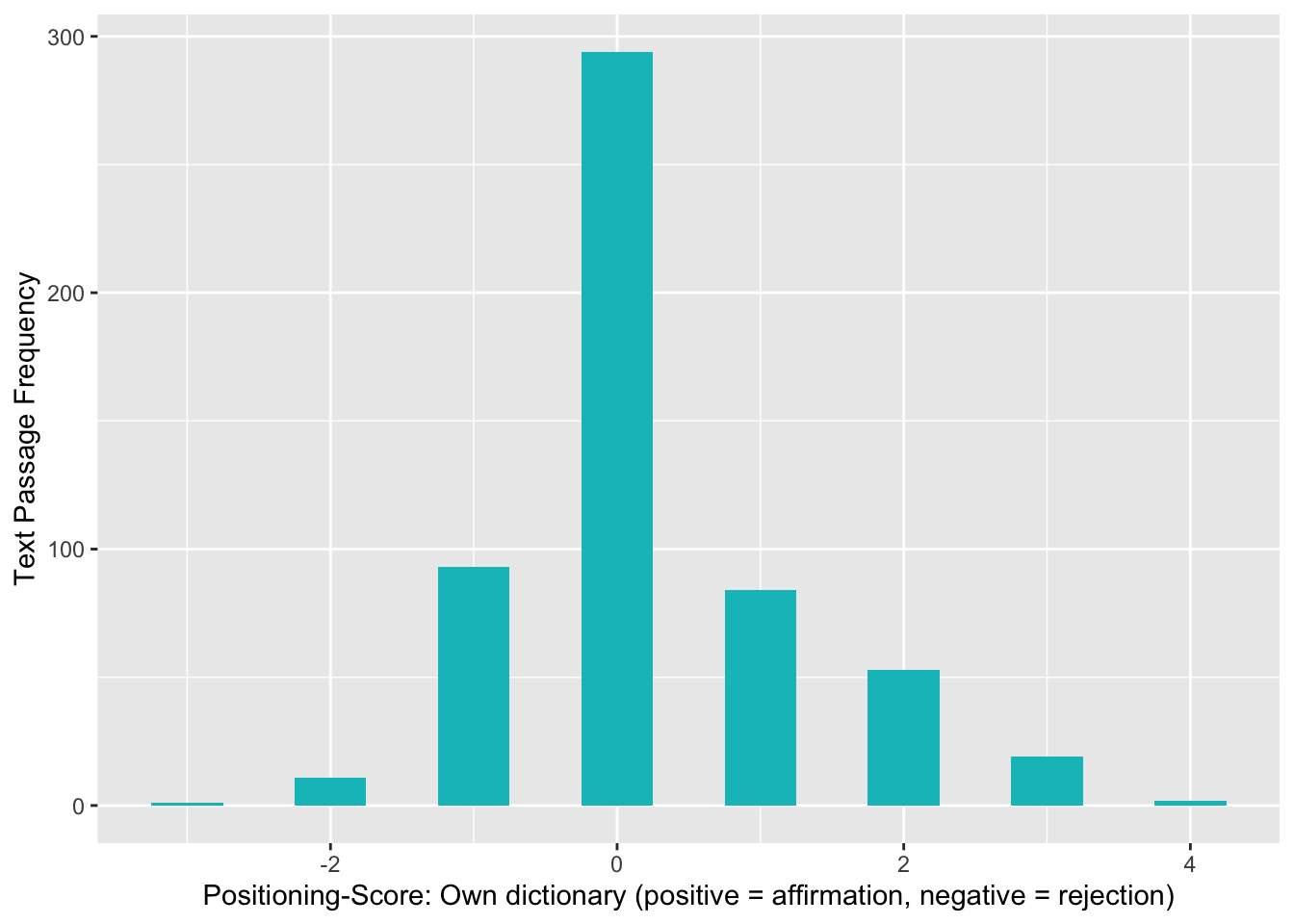
Andererseits erstelle ich selbst ein einfaches Dictionary mit Begriffen, welche auf Zustimmung oder Ablehnung hinsichtlich der Abstimmung hinweisen. Für beide Wörterbücher wird für jede Textpassage ein Wert berechnet, welcher sich aus der Summe der gefundenen positiven & negativen Begriffen ergibt. Damit wird jeder Textpassage eine Punktzahl für ihre Tonalität zugeordnet. Wenn diese Zahl negativ ist, ist die Textpassage hinsichtlich der Abstimmungsempfehlung mutmasslich ablehnend - und vice versa.
# Own dictionary
dict.referendum <- dictionary(
list(
positive = c("ja-*", "ja", "befürwort*", "bejah*", "pro-*", "unterstütz*"),
negative = c("nein-*", "nein", "dagegen", "bekämpf*", "gegner*", "abgeleh*", "ablehn*", "contra-*")))
dfm.senti <- tokens.assocs %>%
tokens_lookup(dictionary = dict.referendum) %>%
dfm()
df.senti <- dfm.senti %>% convert(to = "data.frame") %>%
mutate(sentiment = positive - negative) # calculate a combined sentiment score for regression
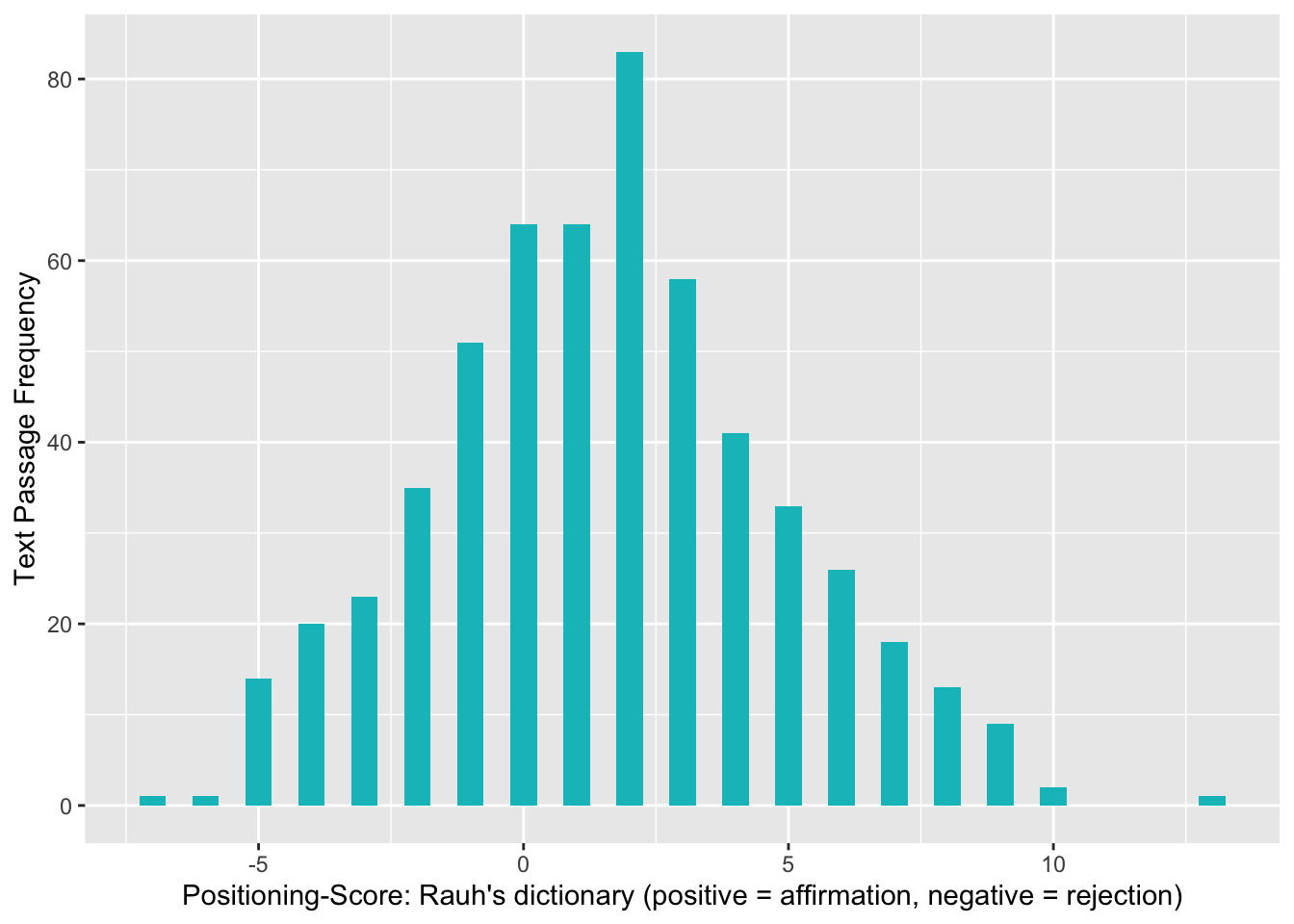
Mit beiden Ansätzen zeigt sich eine ähnliche Verteilung der Tonalitäts-Punkte, welche ungefähr normalverteilt um eine neutrale Tonalität (Nullpunkt) liegt, wobei beim Rauh-Dictionary der Peak ein bisschen im positiven Bereich liegt.
# bind the sentiment scores back to the original dataframe and remove the non matches
senti.assocs <- bind_cols(kwic_assocs, df.senti)
senti.assocs.rauh <- bind_cols(kwic_assocs, df.senti.rauh)
# Plot variable distribution: Self-compiled dictionary
ggplot(senti.assocs, aes(x=sentiment)) + geom_histogram(binwidth=.5, fill=hcl(195,100,65), show.legend = T) +
xlab("Positioning-Score: Own dictionary (positive = affirmation, negative = rejection)") + ylab("Text Passage Frequency")
# Plot variable distribution: Rauh's dictionary
ggplot(senti.assocs.rauh, aes(x=sentiment)) + geom_histogram(binwidth=.5, fill=hcl(195,100,65), show.legend = T) +
xlab("Positioning-Score: Rauh's dictionary (positive = affirmation, negative = rejection)") + ylab("Text Passage Frequency")
3. Bivariater Zusammenhang zwischen Unternehmensverbänden und Tonalität
Das Resultat der Wörterbuchanalyse ist nun ein Datenset mit einer numerischen Variable (Tonalitäts-Punktzahl) und einer kategorialen Variable (Wirtschaftsverband). Dieses kann mit bivariaten Analysen untersucht werden.
Welchen Einfluss hat also der Verband auf die Tonalität? Zu erwarten wäre, dass die Tonalitäts-Punktzahl bei Verbänden der Fossilindustrie besonders negativ ausfällt, da die Gesetzesrevision ihren Profitinteressen in die Quere kommen würde. Zusätzlich zur Prüfung der einzelnen Verbände, fasse ich Verbände auch nach Branchen zusammen und schaue mir an, in welchen Branchen die Gesetzesrevision eher auf Zustimmung trifft und in welchen eher auf Ablehnung. Folgende Zusammenhänge wurden betrachtet:
- UV: Branche, AV: Rauh-Punktzahl
- UV: Branche, AV: Eigenes_Dictionary-Punktzahl
- UV: Wirtschaftsverband, AV: Rauh-Punktzahl
- UV: Wirtschaftsverband, AV: Eigenes_Dictionary-Punktzahl
In der Seminararbeit habe ich auch lineare Regressionsmodelle mit Dummy-Variablen berechnet, für diesen Blog-Post gebe ich lediglich Grafiken der aggregierten Statistiken aus (siehe unten).
Resultate & Diskussion
Mit Rauh’s Wörterbuch korrellieren fast sämtliche grossen Player aus der Fossil- und Flugindustrie mit negativen Werten: Aerodromes (Verband Schweizer Flugplätze), CITEC (Verband der Brennstoff-Tank-Branche), Kaminfeger Schweiz, VFAS (Verband freier Autohändler Schweiz), SHA (Swiss Helicopter Alliance), AVIA (Vereinigung unabhängiger Mineralölimporteure), Aerosuisse (Dachverband der schweizerischen Luft- und Raumfahrt) und Swissoil (Dachverband der Brennstoffhändler Schweiz).
# Create plots with aggregated means for BIAs: Rauh's dictionary
aggr.pattern.rauh <- aggregate(sentiment ~ pattern, FUN=mean, data = senti.assocs.rauh) %>% arrange(desc(sentiment))
ggplot(aggr.pattern.rauh, aes(reorder(pattern, sentiment), sentiment)) +
geom_bar(fill=hcl(195,100,65), stat="identity") + coord_flip() +
xlab("Business Interest Associations") + ylab("Mean of the positioning Score (Rauh's)")
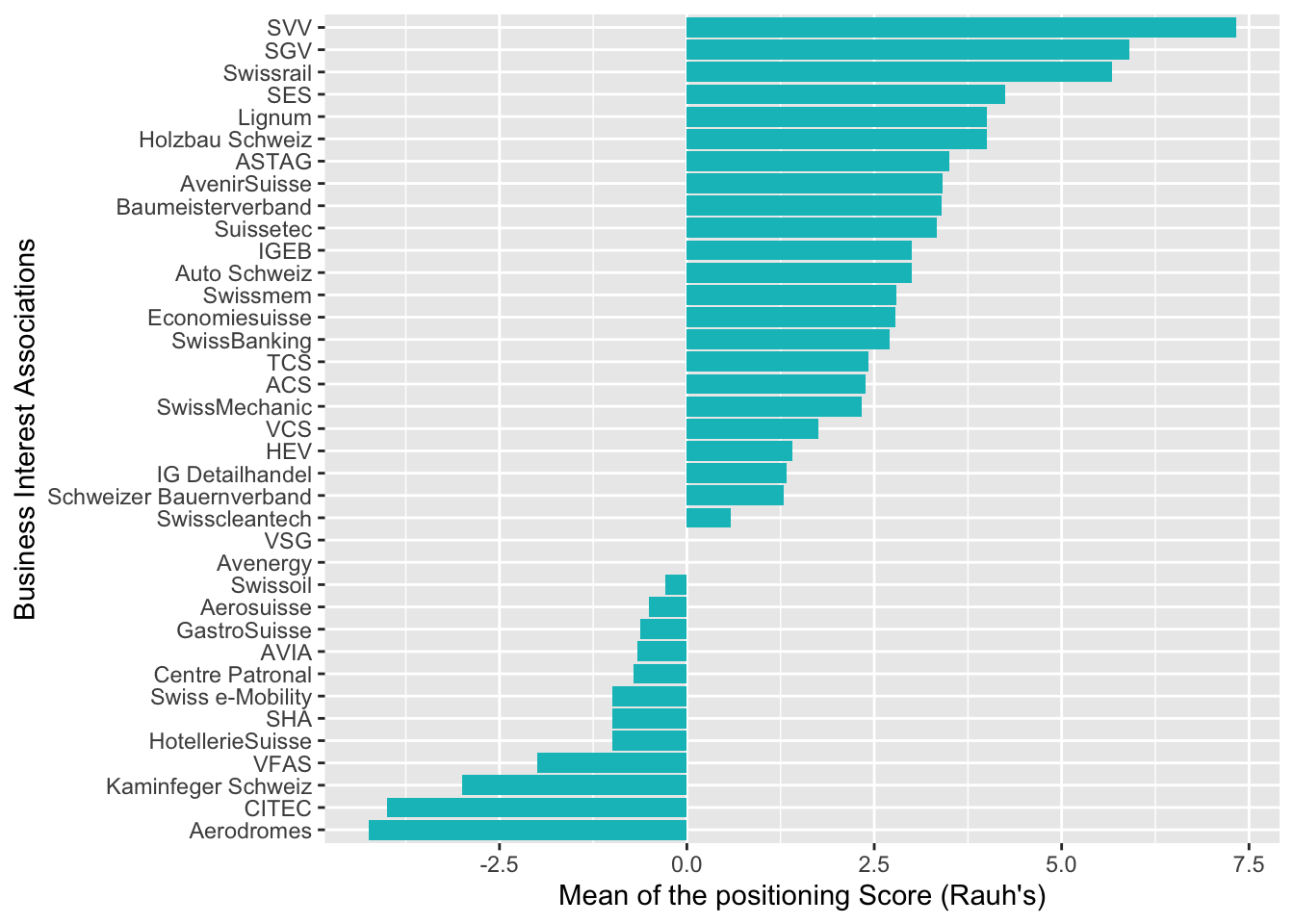
Mit dem Werten des eigenen Wörterbuches schaut es ähnlich aus, auch hier sind es vor allem Verbände aus der Fossilindustrie, welche mit negativer Tonalität korrelieren:
# Create plots with aggregated means for BIAs: Self-compiled dictionary
aggr.pattern <- aggregate(sentiment ~ pattern, FUN=mean, data = senti.assocs) %>% arrange(desc(sentiment))
ggplot(aggr.pattern, aes(reorder(pattern, sentiment), sentiment)) +
geom_bar(fill=hcl(195,100,65), stat="identity") + coord_flip() +
xlab("Business Interest Associations") + ylab("Mean of the positioning Score (Own)")
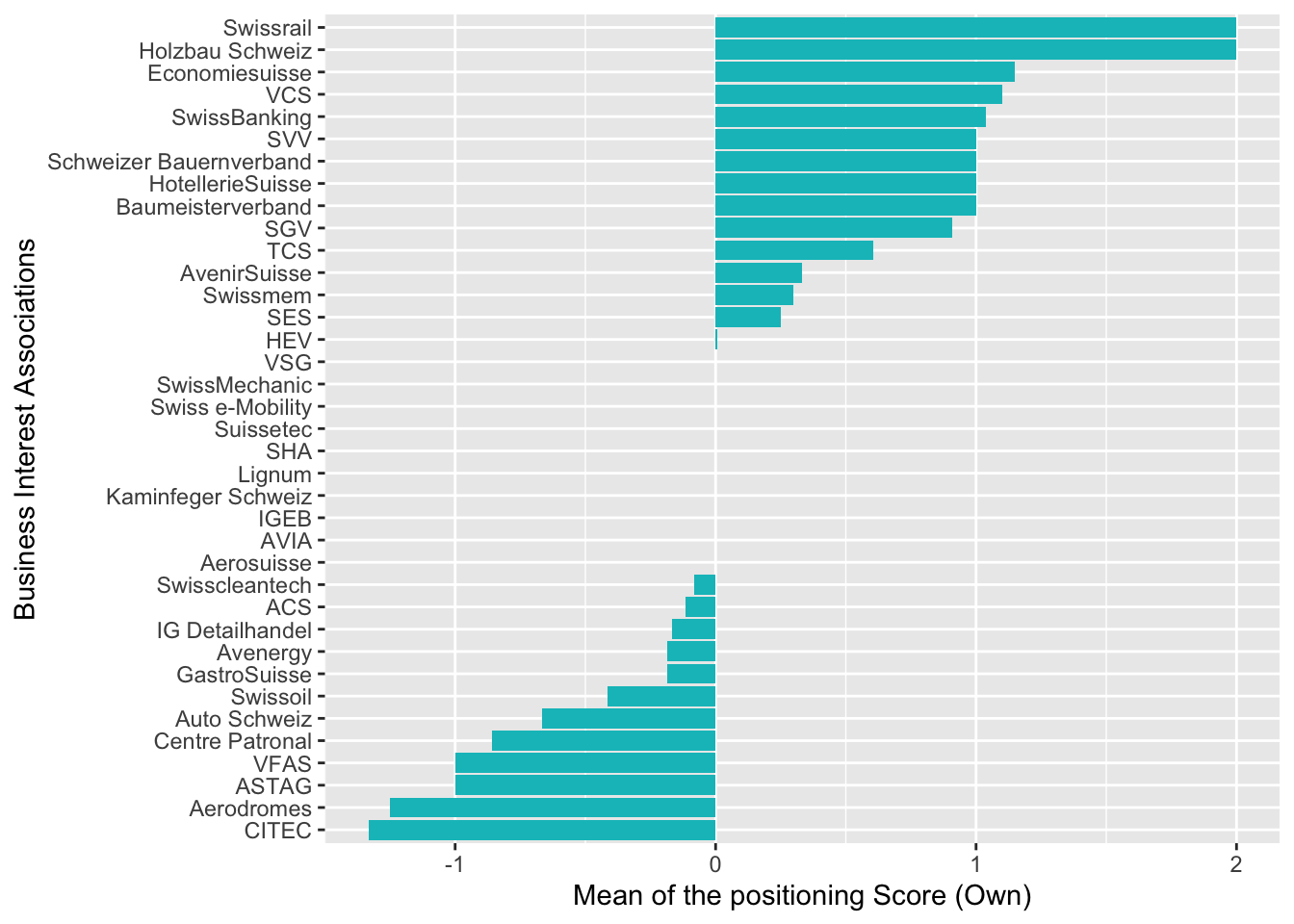
Im positiven Wertbereich fallen vor allem Swissrail (Verband der Schweizer Bahn- und Mobilitätsindustrie) und Vertreter der Baubranche (Holzbau Schweiz, Baumeisterverband, Suissetec) auf. Diese haben sich vom neuen Gesetz vermutlich positive Effekte auf ihre Geschäftsfelder erhofft (Isolations-Sanierungen, Heizungstausch oder Mobilitätswende).
Die Resultate nach Branchen sind weniger deutlich, was womöglich u.a. dem Umstand geschuldet ist, dass die Branchen teilweise Verbände mit entgegengesetzten Interessen beinhalten. Mit dem eigenen Wörterbuch schneidet die Fossil-Lobby jedoch auch hier am negativsten ab, mit einem Wert von -0.29. Auffällig ist auch die Ablehnung im Gastro-Bereich, welcher sich teilweise auch schon oben gezeigt hat (HotellerieSuisse, GastroSuisse).
# Create plots with aggregated means for BIA categories: Self-compiled dictionary
aggr.category2 <- aggregate(sentiment ~ Category2, FUN=mean, data = senti.assocs) %>% arrange(desc(sentiment))
ggplot(aggr.category2, aes(reorder(Category2, sentiment), sentiment)) +
geom_bar(fill=hcl(195,100,65), stat="identity") + coord_flip() +
xlab("BIA Category") + ylab("Mean of the positioning Score (Own)")
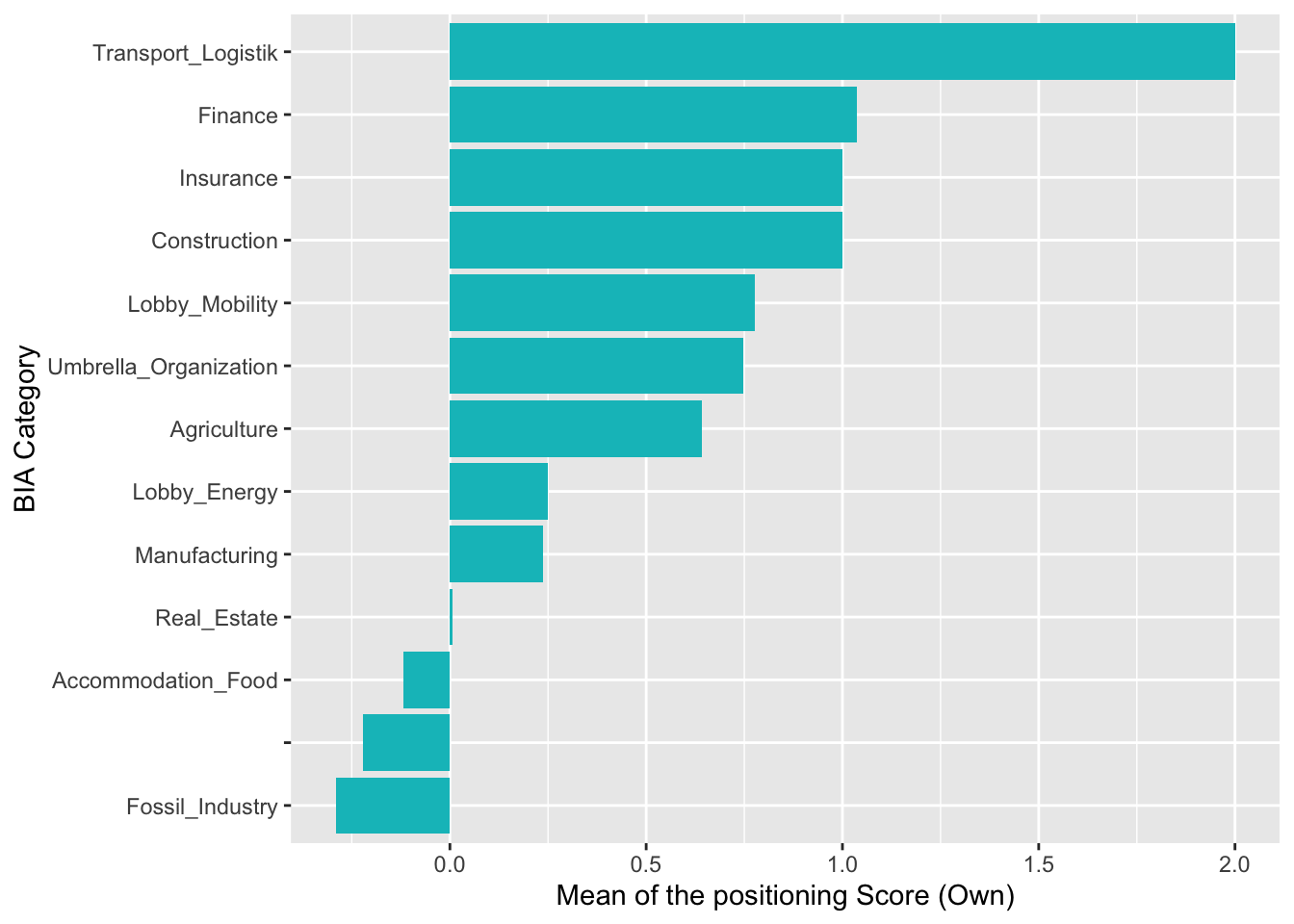
Diese Ablehnung in der Gastro zeigt sich mit dem eigenen Wörterbuch noch deutlicher. Die Gastro Lobby korreliert hier sogar mit noch negativeren Werten als die Fossilindustrie, welche auf zweitletztem Platz liegt, jedoch hier sogar mit leicht positivem Score. In beiden Branchenmodellen fallen der Transport/Logistiksektor, die Baubranche sowie Finanz- und Versicherungssektor als Befürworter auf.
# Create plots with aggregated means for BIA categories: Rauh's dictionary
aggr.category2.rauh <- aggregate(sentiment ~ Category2, FUN=mean, data = senti.assocs.rauh) %>% arrange(desc(sentiment))
ggplot(aggr.category2.rauh, aes(reorder(Category2, sentiment), sentiment)) +
geom_bar(fill=hcl(195,100,65), stat="identity") + coord_flip() +
xlab("BIA Category") + ylab("Mean of the positioning Score (Rauh's)")
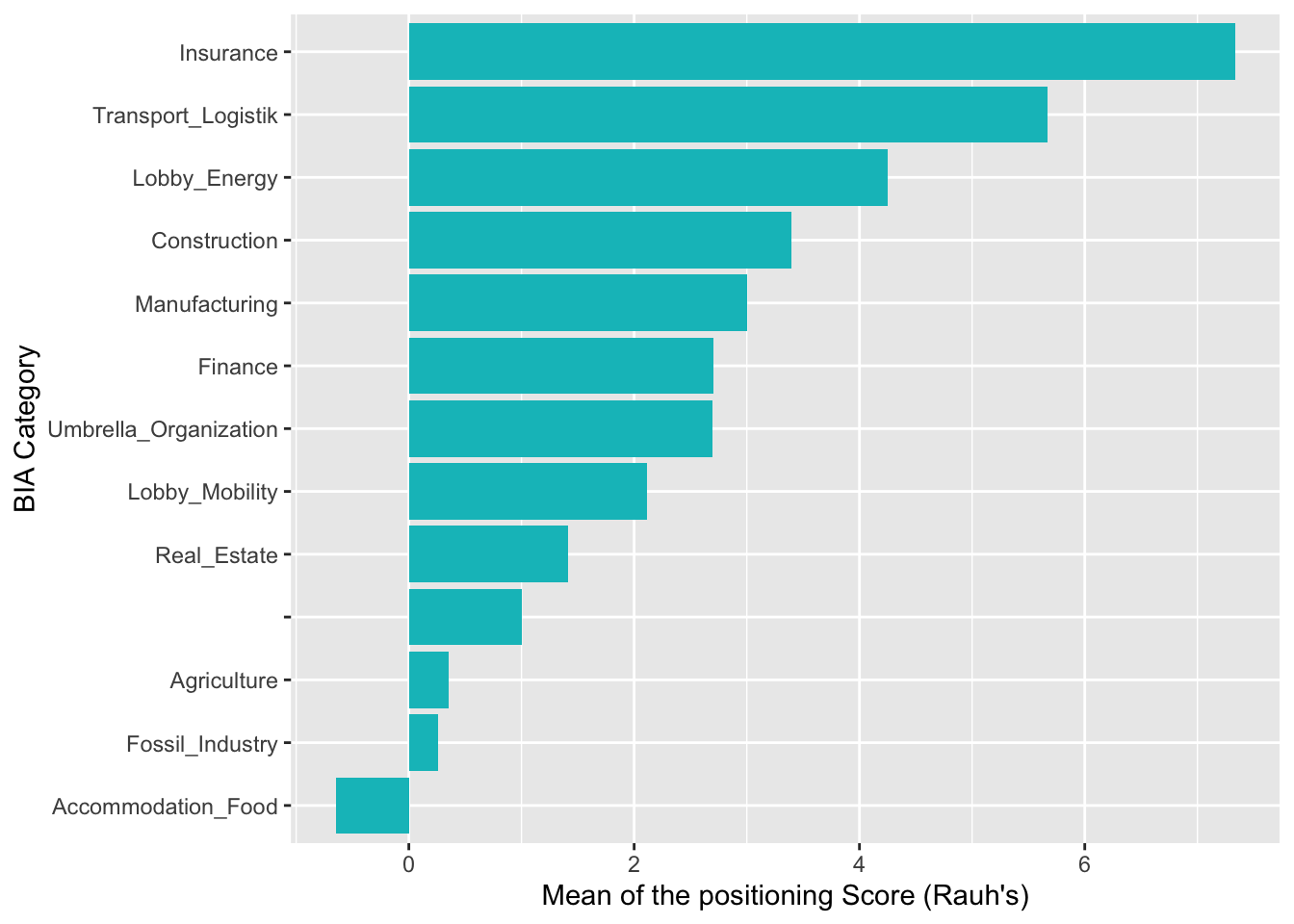
Fazit
Die Resultate bestätigen die Erwartungen: Von allen Branchen ist es die Fossil-Lobby, welche sich medial am deutlichsten gegen die CO2-Gesetzesrevision positionierte. Die Furcht vor Entwertung ihres Kapitals durch Schritte hin zu einer ökologischen Transformation, liess die Fossilindustrie zum fakultativen Referendum greifen. Die Lobby wusste sich in der Phase der Meinungsbildung medial sichtbar zu machen.
Methodisch scheint sich dieser Ansatz zu eignen, um die Positionierung von Wirtschaftsverbänden hinsichtlich Volksabstimmungen zu messen und ihre Position auch in ihrer Stärke quantifizieren zu können. Das Verfahren habe ich in meiner Seminararbeit allerdings nicht validiert. Dies müsste gemacht werden um die Validität der Ergebnisse näher zu prüfen.
Wenn sich der Ansatz bewährt, könnte er auch für andere Entitäten (Parteien, Personen) verwendet werden. Durch eine dynamische Implementierung liesse sich vor Abstimmungen, eine Art Stimmungsbarometer unterschiedlicher Verbände/Entitäten umsetzen. Würde dieses Wissen in Echtzeit in die öffentlichen Debatten zurückgespielt, könnte es wiederum - als Reflexion auf die öffentliche Debatte - die Meinungsbildung selbst beeinflussen.